
So someone was asking if I ran LM Studio locally and I said no, and they said Ollama and I said no, llama.cpp directly, and they were like isn’t that pretty bare bones and hard to use and keep up? So I promised a screen grab and a bit of exposition. Rather than send it by email though, I’m just gonna post it for you. So, here we go.
First thing, I run a multi-system setup. I have two headless ThinkCentre m93p tiny machines for the actual agents. Each one is a Core i5 with 16GB RAM and 230GB SSD. They run headless and each one is about the size of three old CD jewel cases stacked on top of each other, so two m93p systems is still… almost no space at all. Right now, one is OpenClaw and one is running multiple coding harnesses. Having each of them in their own metal gives more safety re: access to the local environment without me having to futz around with virtualization.
I interact with the claw mostly on Discord and the others Tailscale SSH.
Inference actually runs on the machine I interactively use, which is a 3-GPU setup with 76GB VRAM total along with a Core i9-9660k and 128GB DDR4. Two of them are Radeon Pro data center cards, it requires a bit of hacking and home engineering to use these safely as they don’t have onboard active cooling. 3D printer is your friend here. I run actually a fairly stable model selection, almost always Qwen 3.5 122B on the GPUs plus Qwen 3 Embedding in CPU just for memory and vector search stuff.
I then have a service set up with systemctl that launches a bunch of scripts that are bunged into a tmux session. Each script is lightly watchdogged so that if it goes down, the crash is logged and it comes back up and of course if the whole mess goes down systemd brings the service back up from scratch. So the tmux session is available on boot if I choose to attach to it, and of course if I’m remote (say, with Discord on a laptop) I can still open a shell, ssh in, and attach to the tmux session to monitor if I want. It looks like this:
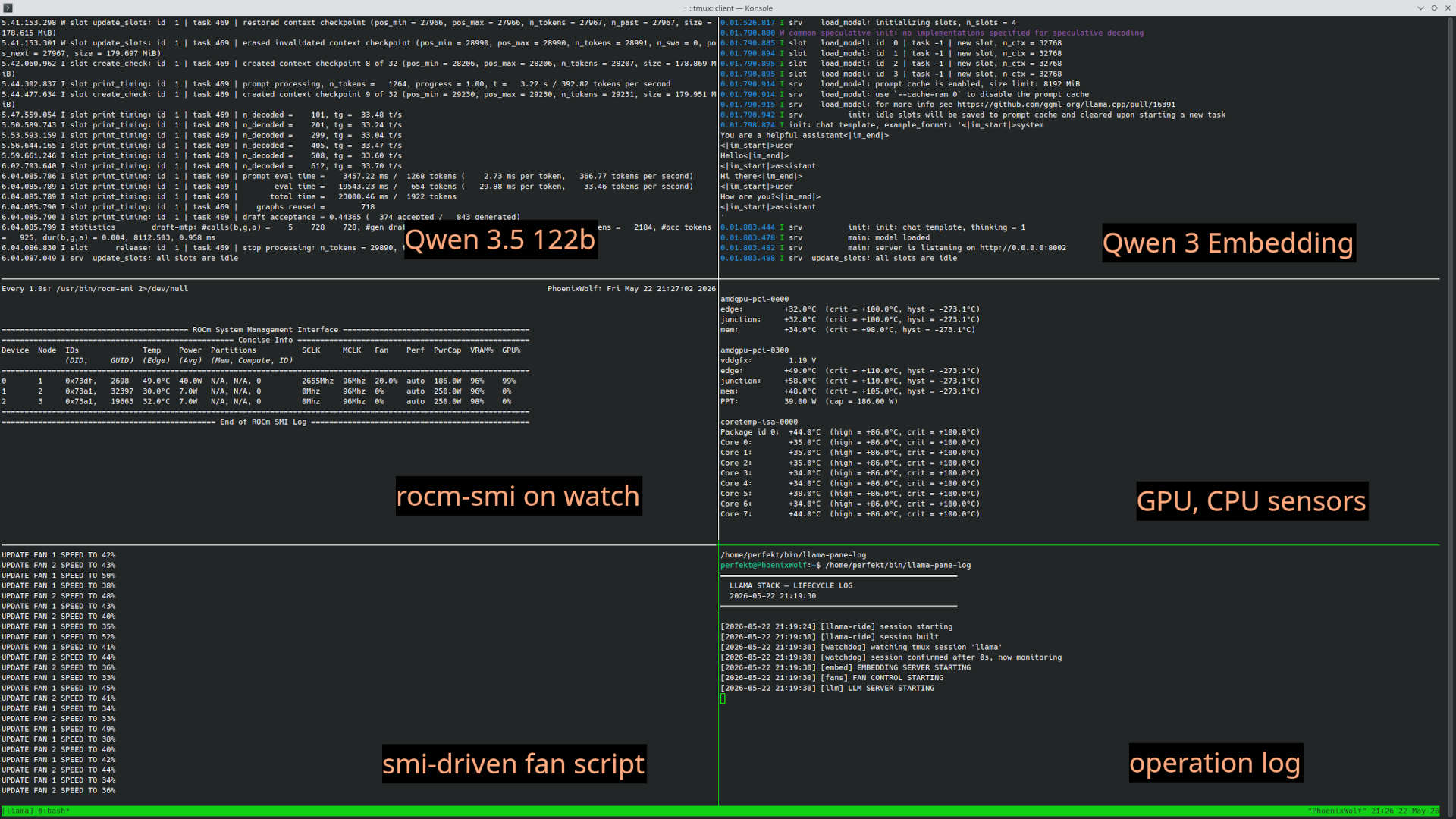
Point being, I treat both inference and embedding just as an OS service that’s always running in the background on different ports, I don’t really treat it like an app. The claw agent is also just a service, it’s always running on its headless machine, it hasn’t been offline since Feb. except to run updates (always an adventure with OpenClaw). The other machine with the coding harnesses is closer to “app” use as those really aren’t doing anything unless I log in to start/use them. But for the most part, when I said “mine is more like infrastructure” that what I meant. I don’t really play with models much. I did early on, but it quickly became clear that Qwen 122B is the hot target for balancing performance and quality for any VRAM quanity from 64GB to probably four times that. Nothing else really comes close.
Right now I’m running ROCm from the lemonade repository. At first I was compiling from AMD myself but that was a PITA to track releases and with stuff happening so fast, I’m happy to let someone else build for me so now I just run lemonade’s llama as they track the nightlies and get all of the latest merges and the build is stable and performant. The v620s aren’t the fastest things on earth for this role as they were clearly intended for partitioned/multi-tenant graphics workloads and lack P2P BUT they’re cheap as dirt and have 32GB VRAM each, so if you’re okay with 35 tokens/sec chat and 50-60 tokens/sec code, they’re a way to get to a 122B model locally without spending what it costs to buy a car.
Oh, I forgot, I also route the whole thing through LiteLLM, which runs on the same machine as the inference, in order to get a working version of /v1/responses/ rather than /v1/completions/ as responses caching behavior is more sane, and that’s important at 122B so that you don’t have to re-run the entire prefill each turn, as that would be painful, especially with claw-based agents as they run with like 50k context at the first turn (which is also why nobody wants to run them on paid tokens). Completions is supposed to be okay at this, but practice says it’s not, responses is better.
All of this said, there are also more changes coming. There is an X399 board and a Threadripper waiting to replace the i9-9900k momentarily so that even without P2P we at least get x8/x16 to CPU independently for each card, rather than x4 shared amongst the entire PCIe pool. I also have another v620 to add (for 108GB VRAM total, which will let me move from q4 to q6 on the 122B model and open up to the full 256k context). There will probably be two rounds of changes here. The 9900k -> Threadripper will be relatively easy on some upcoming Saturday. The third v620 is a bit harder, as I have to figure out how to power it. 😀 I have a 1200W PSU now and a fat case, but I may need a 1500W when all is said and done. I definitely will need more connectors than I currently have. Each GPU is 2x 12v connectors and of course the mainboard wants more, too, post switch. So… the problem isn’t the high tech stuff, as always these days the complexity is ironically in good old fashioned wires and amps.
But anyway, that’s all to-do.
Hope that’s helpful!